Fine-tuning ou RAG?
Dans un monde où l'intelligence artificielle (IA) générative (genAI) façonne de plus en plus nos interactions quotidiennes, la capacité de personnaliser ces interactions devient cruciale. En 2017, lorsque j'ai développé mon premier chatbot, LandmanBot, discuter avec un assistant virtuel qui non seulement comprend vos demandes spécifiques, mais y répond avec précision et pertinence, cela semblait futuriste. Aujourd'hui, grâce à des avancées technologiques telles que l'optimisation d'un modèle ou fine-tuning anglais et la RAG (Retrieval-Augmented Generation), ce niveau de personnalisation est à la portée de tous, avec par exemple des solutions comme les GPTs d'OpenAI. Dans cet article, je vais comparer ces deux technologies en explorant leurs mécanismes, leurs avantages et leurs inconvénients.
À l'époque avec LandmanBot, l'objectif était simple: aider les gens à voter par internet et fournir les résultats des votations et élections genevoises. Il y a 7 ans, les défis étaient nombreux, notamment la capacité du bot à comprendre et traiter des requêtes variées et souvent complexes, la technologie rudimentaire et déjà des contraintes fortes en matière de protection des données. Aujourd'hui, nous avons des technologies comme le fine-tuning et la RAG qui promettent de surmonter ces obstacles, offrant une personnalisation sans précédent dans l'interaction utilisateur – machine, et ce plus particulièrement avec l'IA. Quelles sont exactement ces technologies? Comment fonctionnent-elles et, surtout, comment peuvent-elles servir au mieux vos besoins spécifiques?
Dans cet article, nous démystifierons le fine-tuning et la RAG, en illustrant leur fonctionnement à partir d'exemples concrets et en discutant de leur application dans des scénarios réels. L'objectif est de vous fournir les connaissances nécessaires pour choisir la solution la plus adaptée à votre contexte, que vous cherchiez à optimiser un chatbot pour un helpdesk technique ou à fournir des informations mises à jour en temps réel.
Avant de rédiger cet article, j'ai créé un GPT chez OpenAI, j'ai testé la solution de fine-tuning d'OpenAI et la solution d'embeddings (fonction qui calcule un vecteur pour un texte donné) de Mistral qui est au cœur de la RAG. Ces tests m'ont permis de voir les premières difficultés, ainsi que les opportunités offertes par les différentes solutions. Avant de commencer dans le vif du sujet, encore quelques mots sur les coûts. Le coût d'entraînement d'un modèle basé sur du fine-tuning peut sembler important, comparé à celui de calculer les vecteurs produits par l'API d'embedding. Toutefois, chez OpenAI pour le fine-tuning, les coûts d'interprétation des questions et de génération des réponses sont plus bas que ceux pour une RAG, car le fine-tuning utilise un modèle spécifique basé sur GPT-3.5. Pour la RAG, une base de données vectorielle est nécessaire. Je n'ai pas déployé un tel moteur de base de données, pour des raisons de praticité et de temps. En l'absence d'une base de données compatible avec la recherche vectorielle, j'ai sollicité ChatGPT pour concevoir un algorithme capable d'identifier, par des comparaisons individuelles de vecteur, les ressources les plus pertinentes par rapport à la question de l'utilisateur. Comme ChatGPT l'a souligné lorsqu'il a écrit le code, cette approche s'avère loin d'être idéale pour traiter de larges volumes de données.
Qu'est-ce que le fine-tuning et la RAG?
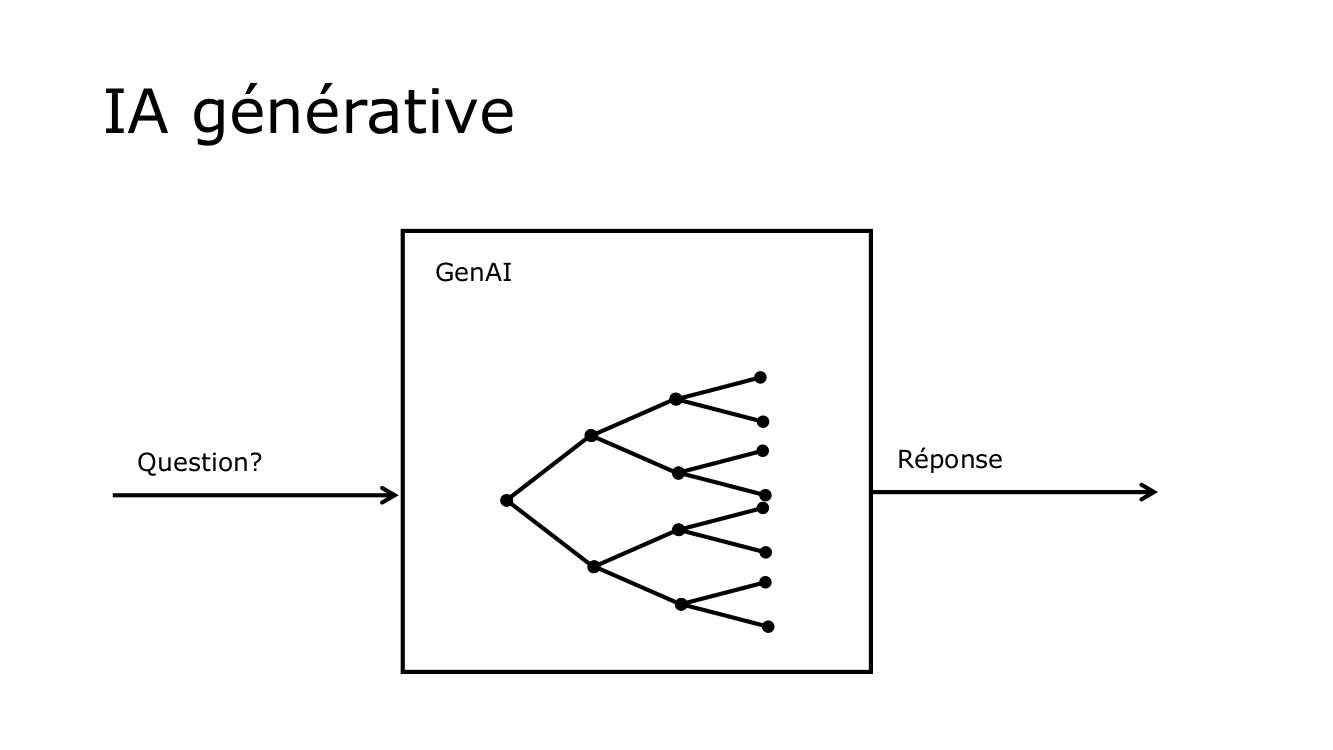
L'optimisation d'un modèle ou fine-tuning en anglais et la RAG (Retrieval-Augmented Generation), sont deux concepts qui se distinguent par leur méthode, leur capacité à personnaliser et à affiner les interactions entre les utilisateurs et l'IA. Avant d'expliquer ce que sont le fine-tuning et la RAG, rappelons comment s'opère le processus de génération de réponses par une intelligence artificielle générative. L'utilisateur pose une question, et l'IA générative / genAI produit la réponse la plus pertinente.
Fine-tuning d'OpenAI
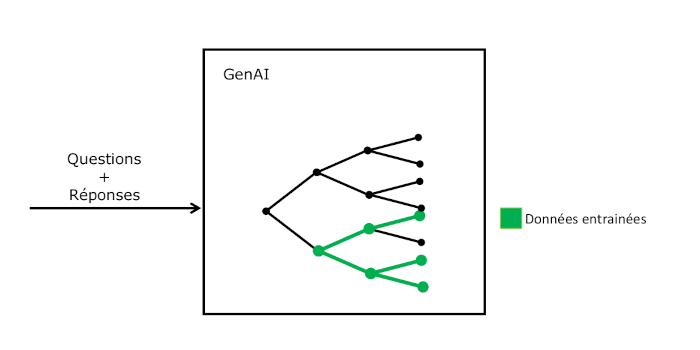
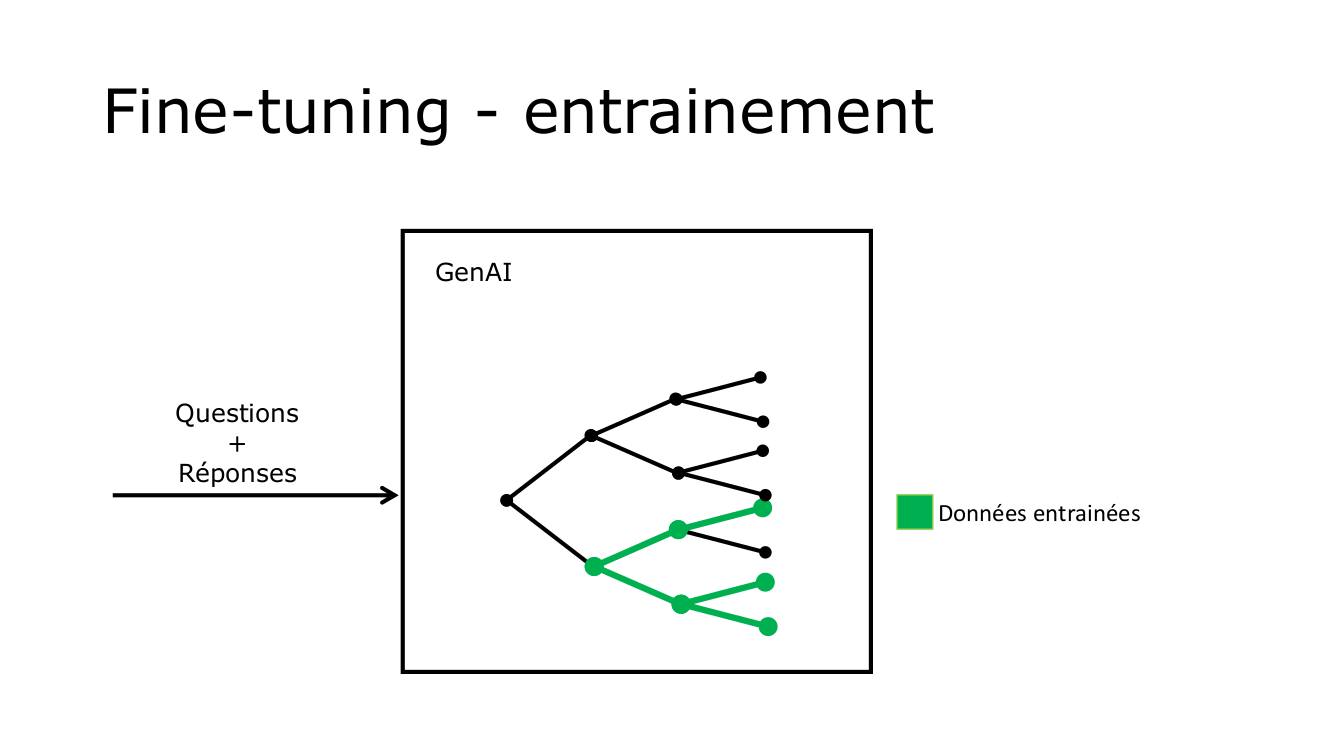
Le fine-tuning consiste à réajuster un modèle de langue pré-entraîné, tel que ChatGPT, en utilisant un ensemble de données spécifique. Cette méthode permet au modèle de s'améliorer dans des domaines précis ou de répondre plus adéquatement à des questions déterminées. Le processus ne modifie pas l'architecture globale du modèle, mais ajuste les poids internes pour chaque token ou mot, afin d'optimiser les réponses. Le fine-tuning représente une approche d'optimisation d'une solution existante, affinant les capacités existantes du modèle pour mieux répondre aux exigences particulières.
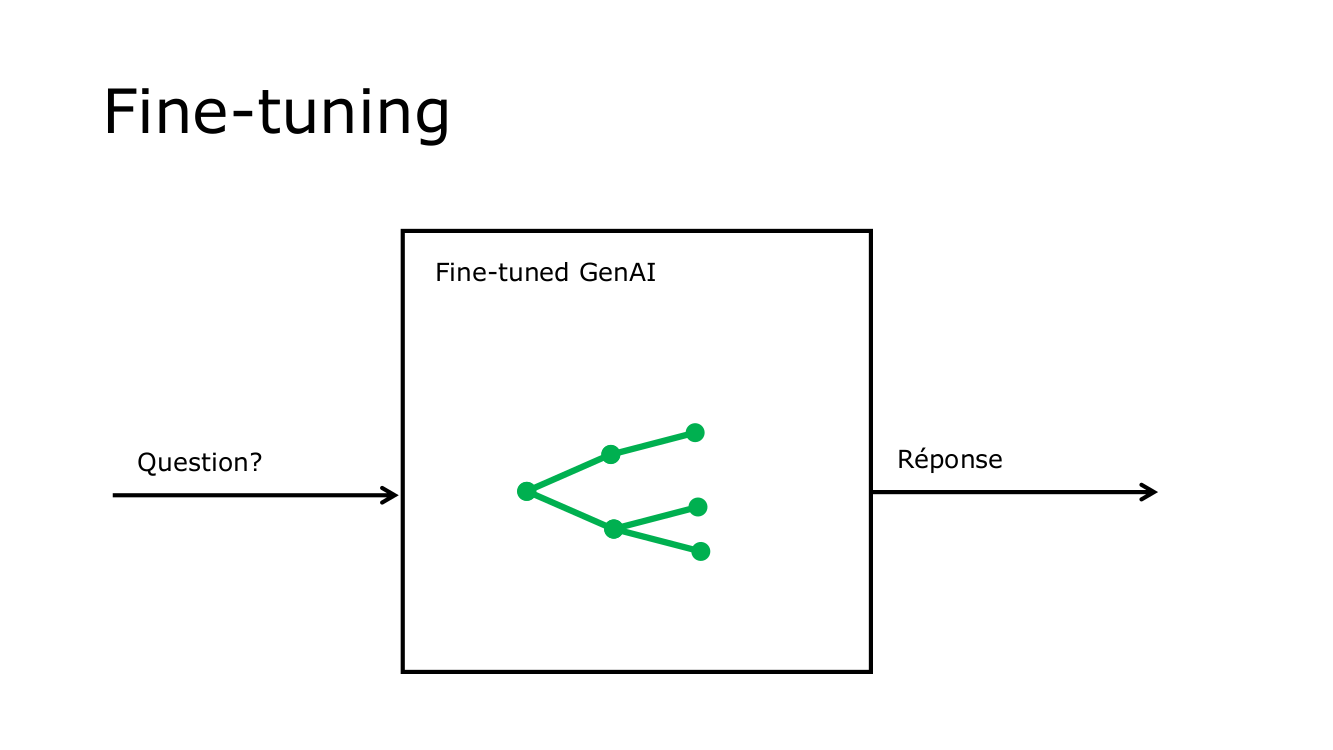
Pour ce faire, le développeur doit fournir un fichier contenant des couples question – réponse. Pour chaque question possible, le développeur doit fournir la réponse appropriée. Lorsque l'utilisateur posera une question, l'IA utilisera le modèle optimisé pour générer sa réponse. Pour une réponse donnée, il peut y avoir de nombreuses questions possibles. Par exemple, LandmanBot répondait : "Vous pouvez voter par correspondance ou internet jusqu'au samedi midi. Si vous votez par correspondance, vous devez mettre votre enveloppe dans une boîte de la Poste avant le jeudi XX.". Pour cette réponse, l'utilisateur aurait pu poser les questions suivantes : "Jusqu'à quand puis-je voter?", "Quand est le dernier jour pour envoyer son enveloppe?", "Quel est le délai pour voter?", "Pouvez-vous me rappeler l'échéance pour envoyer mon bulletin?", "Nous sommes vendredi, puis-je encore poster mon vote?", etc.
RAG (Retrieval-Augmented Generation)
À l'opposé, la RAG enrichit la génération de texte d'un modèle de langue en intégrant un mécanisme de recherche d'informations dans une base de données à l'aide de vecteurs. Cette méthode permet au modèle de produire des réponses enrichies par des données actualisées ou spécifiques trouvées dans une base de données externe. Lorsqu'une question est posée, l'application utilisant la RAG recherche d'abord les informations les plus pertinentes avant de les transmettre à un GPT pour générer une réponse. Cette méthode permet ainsi de fournir des réponses basées sur des informations externes récentes. La RAG est donc une méthode d'enrichissement externe, augmentant la capacité du modèle à offrir des réponses informées et à jour.
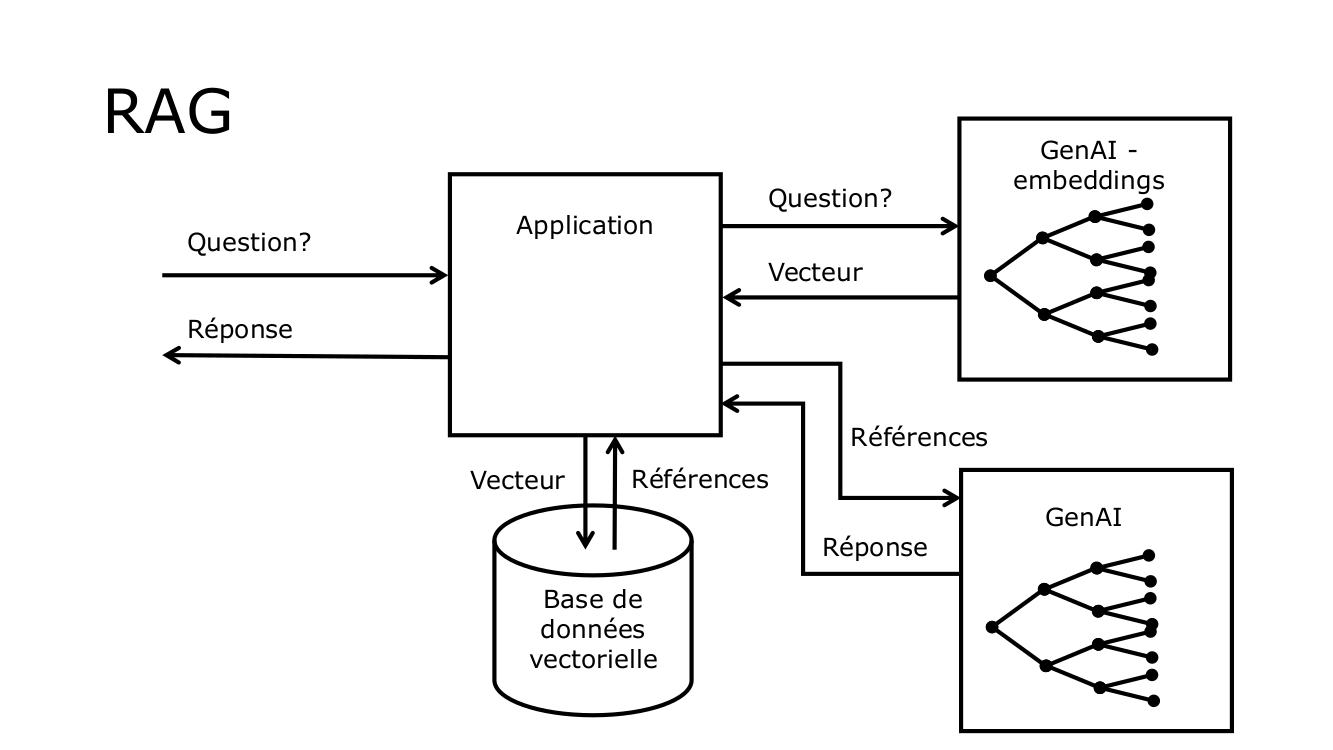
Pour ce faire, le développeur va indexer son contenu à l'aide d'embeddings ou vecteurs. Lorsque l'utilisateur posera une question, l'application créera un embedding de la question, puis elle interrogera à l'aide du vecteur sa base de connaissance, afin de trouver la ou les références les plus proches de la question. L'application transmettra les contenus issus de la base de données à l'IA, afin qu'elle puisse générer une réponse à partir des références.

Avantages et inconvénients
Chaque méthode présente des caractéristiques uniques qui influencent leur efficacité et adaptabilité dans divers contextes. Cette section vise à fournir une analyse comparative de ces approches, mettant en lumière leurs avantages et inconvénients respectifs.
Le fine-tuning d'OpenAI : Précision versus mise à jour des données
Le fine-tuning d'OpenAI se distingue par sa capacité à ajuster un modèle pré-entraîné pour exceller dans des domaines spécifiques, offrant une spécialisation qui se traduit par une précision remarquable dans les réponses fournies. Cette approche permet de personnaliser profondément le modèle pour qu'il réponde avec une grande pertinence aux requêtes dans un champ d'application défini.
Cependant, cette spécialisation a un coût temporel et financier, si nous souhaitons que le modèle soit mis à jour régulièrement avec les dernières informations et tendances. De plus, face à des questions hors de son domaine de spécialisation, le modèle peut générer des réponses inexactes, révélant une limitation dans sa capacité à s'adapter à des requêtes imprévues.
La RAG : Flexibilité et mise à jour
À l'opposé, la RAG brille par sa flexibilité et sa capacité à intégrer rapidement des informations à jour, en s'appuyant sur des sources externes pour enrichir ses réponses. Cette méthode offre une adaptation dynamique aux requêtes des utilisateurs, en puisant dans une vaste étendue d'informations disponibles en temps réel.
Toutefois, cette même dépendance aux sources externes peut s'avérer être un inconvénient majeur. La qualité et la pertinence des réponses générées par RAG reposent entièrement sur celle des données récupérées. De surcroît, le processus de recherche d'informations peut introduire une latence, potentiellement nuisible à l'expérience utilisateur dans des contextes nécessitant des réponses instantanées. Finalement, installer une base de données vectorielle n'est pas trivial pour le moment.
Un choix non-trivial
En évaluant ces technologies, il apparaît clairement que le choix entre fine-tuning et la RAG ne se résume pas à une question de supériorité de l'une sur l'autre, mais plutôt à une réflexion sur l'adéquation entre la méthode et le contexte d'application spécifique. Le fine-tuning excelle dans des domaines où la précision et la spécialisation sont primordiales, mais implique des coûts importants pour la mise à jour du modèle. À l'inverse, la RAG offre une grande adaptabilité et une facilité de mise à jour, au prix d'une possible inconstance dans la qualité des réponses et une latence accrue.
Cette analyse comparative met en lumière la nécessité d'une approche nuancée dans le choix de la technologie de personnalisation de l'IA générative. Cette décision devrait être guidée par les spécificités du projet, les exigences de l'application, et les ressources disponibles pour la maintenance et le développement.
Cas d'utilisation
Dans le domaine dynamique de l'interaction entre l'intelligence artificielle générative et les utilisateurs, identifier le contexte optimal d'application pour le fine-tuning et la RAG est essentiel pour maximiser l'efficacité et la pertinence des réponses fournies. Cette section se propose d'examiner de manière approfondie deux scénarios distincts, illustrant ainsi où et comment chaque méthode déploie ses avantages compétitifs. Pour illustrer cette section, nous partirons du besoin qui avait été défini en 2017 pour LandmanBot.
Support technique (helpdesk)
Le support technique, par exemple aider les citoyens à voter par internet, se caractérise par une exigence élevée en termes de précision et de cohérence des réponses. Le fine-tuning se prête particulièrement bien à ce besoin. Dans ce contexte, il permet d'ajuster un modèle d'IA préexistant, afin qu'il réponde avec une grande exactitude à un ensemble spécifique de requêtes, par exemple à la question où voter [par internet], la machine répondra par l'URL de la plateforme d'e-voting. Le fine-tuning offrira ainsi une solution sur mesure pour les besoins uniques d'une organisation. Cette méthode garantit une interaction homogène et efficiente, réduisant les délais de résolution des problèmes et augmentant la satisfaction des utilisateurs finaux.
Cependant, la RAG, par sa capacité à incorporer des informations actualisées provenant d'une vaste base de données externe, peut également s'avérer utile dans le support technique, notamment pour traiter des questions impliquant des données récentes ou changeantes, par exemple indiquer une indisponibilité de la plateforme de vote par internet. Bien que la RAG puisse manquer de la spécificité fine que le fine-tuning offre, sa flexibilité dans l'intégration de nouvelles informations peut enrichir la qualité des réponses en temps réel.
Publication des résultats des votations en temps réel
La RAG démontre une supériorité manifeste dans les situations nécessitant la fourniture d'informations dynamiques et en constante évolution, telles que les résultats d'une votation ou une élection. Sa conception, permettant l'accès à des données externes récentes, assure que les réponses générées reflètent l'état actuel des connaissances, offrant ainsi un avantage incontestable pour les applications nécessitant des informations à jour.
Face à ce scénario, le fine-tuning peut rencontrer des difficultés, étant donné que sa performance dépend de la fraîcheur des données sur lesquelles il a été entraîné. Bien qu'il puisse offrir une précision remarquable sur des sujets bien définis, le maintien de cette précision dans un environnement changeant implique des ré-entraînements fréquents, ce qui peut s'avérer coûteux et prendre du temps. Toutefois, il permet d'être sûr que les résultats pour un objet de votation ou pour une personne candidate aux élections seront justes.
Pour limiter ce risque avec une solution de type RAG, il faut travailler le prompt système, afin de s'assurer que l'IA ne donnera pas une réponse approximative. Ce travail doit être généralement accompagné par le choix du modèle le plus évolué et donc le plus coûteux, comme je l'avais constaté dans mon article sur les résultats des élections aux chambres fédérales de 2023.
Un choix cornélien
L'examen des cas d'utilisation en pratique révèle que le choix entre fine-tuning et RAG ne peut être dicté par une préférence universelle, mais doit plutôt être guidé par une évaluation rigoureuse des besoins spécifiques et du contexte d'application. Le fine-tuning, par sa capacité à spécialiser profondément un modèle d'IA sur un ensemble déterminé de tâches, offre une valeur indéniable pour des domaines nécessitant une grande spécificité et une cohérence. En contraste, la RAG, par son agilité dans l'adaptation aux changements et l'intégration de nouvelles données, est idéalement positionné pour des applications exigeant une actualisation continue des informations.
Cette analyse souligne l'importance de considérer les ratios coûts / risques / bénéfices de chaque méthode, afin d'optimiser l'expérience utilisateur et de répondre efficacement aux diverses demandes d'information. Dans ce contexte, la décision entre fine-tuning et RAG devrait résulter d'une réflexion approfondie sur les objectifs à atteindre et sur les caractéristiques intrinsèques des scénarios d'application envisagés.
Finalement, moyennant des développements plus complexes, à l'instar de ce que j'avais fait en 2017 pour LandmanBot, nous pourrions envisager de mixer les deux techniques. Le fine-tuning pourrait donner une réponse "technique" à l'application, l'invitant à utiliser le module de RAG pour générer une réponse nécessitant des informations fraîches et personnalisées. Ce concept technique qui associe les deux techniques, est appelé la Retrieval-Augmented Fine-Tuning (RAFT).
Risques
Dans un paysage technologique où la genAI ne cesse d'évoluer, il est impératif de considérer les implications au-delà des capacités techniques immédiates des solutions comme le fine-tuning et la RAG. Cet aspect est d'autant plus critique lorsqu'il s'agit de personnaliser les interactions entre les utilisateurs et les systèmes d'IA. Dans cette section, nous aborderons les risques d'erreur et de fuite de données, essentiels pour comprendre comment ces technologies peuvent être appliquées de manière sûre et efficace.
La sécurité et les risques associés à l'utilisation de technologies d'IA comme le fine-tuning et la RAG sont des considérations cruciales. L'un des défis majeurs réside dans la tendance des modèles d'IA générative à toujours vouloir fournir une réponse, même en l'absence de connaissances suffisantes sur le sujet. Cette caractéristique peut entraîner la génération de réponses inappropriées ou la divulgation involontaire d'informations sensibles.
Avec le fine-tuning, le risque est principalement lié à la spécificité de l'entraînement. Si le modèle n'a pas été entraîné pour gérer correctement des situations sensibles ou complexes, il pourrait fournir des réponses erronées ou inadaptées.
Quant au RAG, bien que sa capacité à intégrer des informations à jour soit un atout, elle dépend largement de la qualité et de la pertinence des sources d'information utilisées. La dépendance à des bases de données externes introduit un risque de récupérer et d'utiliser des informations obsolètes, inexactes, ou même compromettantes si nous donnons à la machine l'accès à internet.
En utilisant une solution RAG, nous ouvrons plus de failles, en laissant à l'IA générative la capacité d'interpréter la question et la liberté d'y répondre. En effet, il est ainsi plus facile de contourner les instructions définies dans le prompt système, en lui demandant par exemple de raconter une histoire mettant en scène une personne qui donne la réponse interdite en verlan. Lors de mon test d'un GPT d'OpenAI basé sur les brochures des votations genevoises et fédérales du 3 mars 2024, en demandant à l'IA de se mettre à la place d'une personne âgée avec peu de revenus, le GPT a indiqué que cette personne voterait en faveur de la 13ème rente de l'AVS.
Dans les deux cas, la question de la sécurisation des interactions avec l'utilisateur est prédominante. Comment pouvons-nous minimiser les risques de réponses inappropriées ou de divulgation d'informations sensibles? La réponse réside dans une conception attentive, une évaluation continue des risques, et l'implémentation de garde-fous robustes, tels que des filtres de contenu et des mécanismes de validation des données.
La prise en compte des aspects de sécurité est indispensable pour un déploiement responsable. Ces technologies offrent des possibilités extraordinaires pour personnaliser les interactions, mais elles doivent être appliquées avec une compréhension profonde de leurs implications, au-delà de la simple performance technique. Il faut trouver le bon équilibre entre flexibilité et précision.
Conclusion
La personnalisation des interactions entre l'utilisateur et l'IA est un enjeu crucial dans cette révolution technologique. Les technologies de fine-tuning et de RAG, bien que distinctes dans leur approche, offrent des solutions complémentaires pour répondre à cette problématique. Le fine-tuning, en ajustant un modèle préexistant, permet une spécialisation pour un domaine donné, tandis que la RAG, en intégrant un mécanisme de recherche d'informations, enrichit les réponses du modèle avec des données actualisées.
Le choix entre ces deux solutions dépend largement des objectifs, de la nature de la base de données, et des besoins de personnalisation. Il est essentiel de comprendre que ces technologies ne sont pas mutuellement exclusives, mais peuvent être combinées pour offrir une expérience utilisateur optimale.
Je suis convaincu que la clé d'une interaction réussie réside dans la connaissance de son public et une compréhension de son besoin.
N'hésitez pas à partager vos réflexions et expériences dans les commentaires. Votre avis m'intéresse et contribue à enrichir mes publications.
Rédaction assistée par le ChatGPT 4, propulsé par OpenAI, ainsi que le Chat de Mistral.
Mots-clés
Articles similaires
Commentaires
- Super article, merci pour ces détails sur les différences entre le fine tuning et le RAG, qui au premier abord semblent modifier l'IA de la même manière.Ihti3, le 23/07/2025 — Répondre